本文从大模型应用风险谱图出发,按照大模型应用数据流的顺序梳理OWASP Top 10 LLM 2025中提到的十大安全威胁。
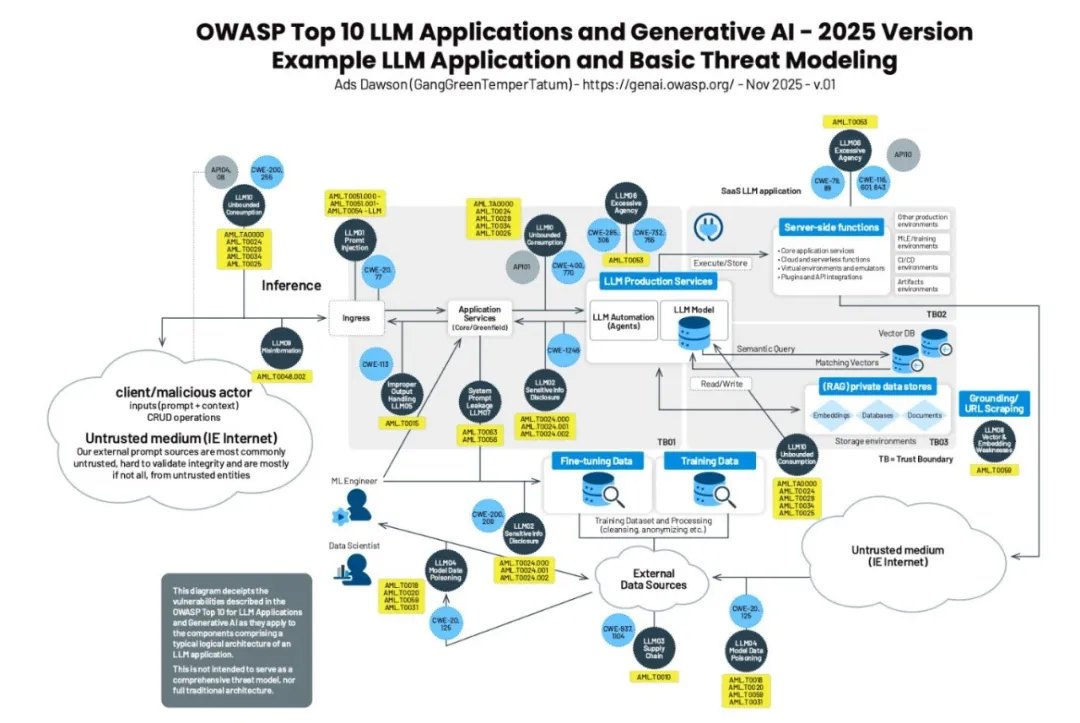
▎无限资源消耗(LLM10 Unbounded Consumption)
攻击者发送大量无用请求,恶意占用大模型服务资源,或者发送大量超过模型上下文窗口限制的请求,导致服务降级或不可用(输入泛滥与溢出)。这类风险一般发生在服务接口层。
甚至有些攻击者发送精心设计的复杂prompt,这些prompt会让后端模型计算时占用大量系统资源,导致服务超时或不可用(资源密集型查询)。这类风险一般发生在模型层,属于模型原生风险漏洞。
攻击者通过频繁操作调用基于云提供AI的服务(按量收费),导致服务提供者账单爆炸(钱包拒绝服务)。这类风险一般发生在模型部署层。
攻击者通过构造海量请求prompt套取模型回复形成答案对,从而倒推模型参数(模型窃取/模型复制)。这类风险一般发生在接口服务层。
▎信息误导(LLM09 Misinformation)
大模型的幻觉问题,包括生成事实性错误(传递信息有误)、无中生有(LLM虚构假的法律安检)、专业能力错误(医疗、金融领域)。
大模型有时候还建议使用不安全的代码或者第三方库,容易引发漏洞。
这类风险往往发生在用户和模型系统的交界面。
▎提示词注入(LLM01 Prompt Injection)
攻击者通过在prompt中植入复杂指令,诱导模型服务生成违反安全规范的内容,或启用未经授权的访问。
提示词注入的类型有很多,常见的有代码注入、对抗性后缀、多语言混淆攻击等等。
这类风险一般都发生在大模型服务的接口层。
▎过度代理(LLM06 Excessive Agency)
大模型服务功能过多、或者权限过高,例如大模型服务除了有读取文档知识库的权限,还有删除、修改的权限,这可能会导致文档内容失控的风险。
另外,大模型或者Agent自主性过强,无需人工干预即可自动对敏感内容文档进行增删改查操作,有很大的潜在风险。
这类风险往往存在于Agent代理层,或者大模型服务调用的各种插件中。
▎向量与嵌入漏洞(LLM08 Vector & Embedding Weakness)
知识库中含有敏感信息,或者鉴权机制设计不足导致敏感信息泄露(数据泄漏)。
知识库中被有意或者无意投毒,导致模型输出泄露敏感信息或者输出被恶意操控(知识库数据投毒)。
多租户共用相同数据库时,攻击者可以通过上下文获取其他用户聊天信息(跨上下文信息泄露)。
▎敏感信息泄露(LLM02 Sensitive Info Disclosure)
敏感信息包括个人隐私信息(PII)、商业隐私信息和模型自身的隐私信息。
这类风险可能发生在用户和模型交互的过程中,也可能发生在训练阶段,算法工程师将未经过滤的敏感信息放入训练数据(预训练/微调数据)。
▎系统提示泄漏(LLM07 System Prompt Leakage)
系统提示信息包括敏感功能(数据库类型)、内部规则(业务规则限制)、过滤条件(安审风控)、权限与角色结构。
▎不当输出处理(LLM05 Improper Output Handing)
攻击者 在未使用参数化查询的情况下执行LLM生成的SQL查询,导致 SQL注入 。
攻击者使用LLM输出构造文件路径,未进行适当清理时可能导致路径遍历漏洞。
攻击者将LLM生成的内容用于电子邮件模板,未进行适当转义时可能导致钓鱼攻击。
攻击者利用LLM的输出直接输入系统命令执行,导致远程代码执行。
攻击者利用LLM生成JavaScript或Markdown代码并返回给用户,代码被浏览器解释后引发XSS攻击。
▎模型数据投毒(LLM04 Model Data Poisoning)
模型的训练数据很多来自外部未经验证的数据源,这些数据里可能还有坏数据。
攻击者可能会在训练数据中刻意埋入毒性数据,导致模型训练结果不可控。
这类风险一般发生在训练阶段。
▎供应链风险(LLM03 Supply Chain)
这类风险包括第三方组件的传统漏洞风险,使用的基座模型安全性弱,设备端硬件漏洞等。
还包括开源模型和组件的许可风险,隐私条款等。
▎几点体会
以上Top10安全风险,有些是模型(系统)自身安全,例如幻觉导致的信息误导。
有些是攻击者有意攻击触发,例如无限资源消耗、提示词注入、不当输出处理、 模型数据投毒、系统提示泄漏。
有些是外界流程或者功能插件的引入导致的新风险,例如敏感信息泄漏、向量与嵌入漏洞、过度代理、 供应链风险。
不同风险之间可能相互交叠,例如提示词注入/模型数据投毒引发的敏感信息泄露。
这也导致了有些防护策略是可以同时防护多种风险的,例如针对输入、输出内容的风险过滤,可以防护提示词注入攻击,同时防止敏感信息泄露。
另外,同一类风险可能存在整个大模型应用的多个环节,例如敏感信息泄露可能发生在训练环节,也可能发生在用户和大模型服务的交互环节。这就要求防护方案也要具备一定的全面性。
诚如《浅谈大模型安全》中所说,大模型安全很难有一个客观统一的框架和规范。
OWASP也是根据业界普遍关注的安全问题,“票选”了呼声最高的10个。
▎关于OWASP
OWASP(Open Web Application Security Project)是一个非营利组织,致力于提高Web应用程序的安全性。
OWASP每年发布一份安全报告(OWASP TOP 10),列出十大常见的Web应用安全漏洞。这份报告是全球公认的标准,帮助开发者和安全专家识别和预防最常见的安全漏洞。
2023年开始,OWASP针对大模型应用领域发布TOP 10安全威胁榜单,旨在突出 并解决 AI 应用特有的安全问题。
▎OWASP Top 10 LLM-2025安全风险与防护策略清单
风险类型 |
风险场景 |
防护策略 |
提示词注入 |
|
约束模型行为 定义格式 输入输出过滤 最小权限访问 人工审批高危动作 隔离外部内容 红蓝对抗 |
敏感信息泄露 |
|
|
供应链 |
|
组件漏洞扫描 许可证审计 使用可验证来源模型 对供应模型和数据进行安全测评 加密端侧模型 |
数据与模型投毒 |
|
验证数据合法性 数据集版本控制 监测训练损失 红蓝对抗 RAG增强 |
不当输出处理 |
|
模型响应验证 模型输出编码 内容安全策略 日志和监控 |
过度授权 |
|
|
系统提示泄露 |
|
敏感数据分离 严格行为控制 外挂防护措施 关键安全控制 |
向量与嵌入漏洞 |
|
权限与访问控制 数据来源质量验证 数据分类审查 监控日志记录 |
信息误导 |
|
增强检索生成 模型微调 交叉验证 AI标识提醒 培训用户 |
无限资源消耗 |
|
输入验证 速率限制 访问控制 AI水印 超时与节流
|