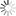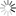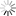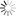2025年9月18日,浙江大学计算机学院院长、区块链与数据安全全国重点实验室常务副主任任奎教授团队联合华为计算产品线,在“华为全联接大会2025”上发布了 DeepSeek-R1-Safe ——国内首个基于昇腾千卡算力平台训练的安全基础大模型。该模型在全流程自主可控的后训练框架下完成训练,整体安全防御能力提升至83%,普通问题安全率接近100%,且通用性能几乎无损。任奎教授因其开创性贡献,获颁华为计算产品线“科研创新卓越贡献奖”。
随着大模型在金融、医疗、制造等行业的广泛应用,安全问题已成为全球公认的挑战。国际上曾曝出 Gemini 被利用发动网络攻击、三星机密外泄 等事件,国内早期模型在越狱测试中的失守率也一度高达100%。这些案例表明,如何在保持性能的同时增强安全性,是亟需解决的关键问题。
DeepSeek-R1-Safe 的推出,正是为应对这一挑战。团队依托昇腾千卡集群,构建了覆盖 安全语料构建—安全模型训练—国产算力平台 的全栈式方案,并通过系统化评测验证了其在多维度上的防御效果和通用性能表现。
技术方案
团队从底层入手,构建了一套覆盖“高质量安全语料—平衡优化的安全训练—全链路自主可控软硬件平台”的全栈式安全训练框架,将安全能力深度嵌入模型的“思考”与“表达”之中。
数据层(安全语料):合规对齐 + 安全思维链 + 越狱对抗样本 + 质控流水线
训练层(安全范式):监督阶段的“安全思维预对齐”与性能补偿;强化阶段的“多维奖励 + 帕累托最优”
平台层(国产工程化):基于昇腾千卡集群的分布式后训练与工具链支撑
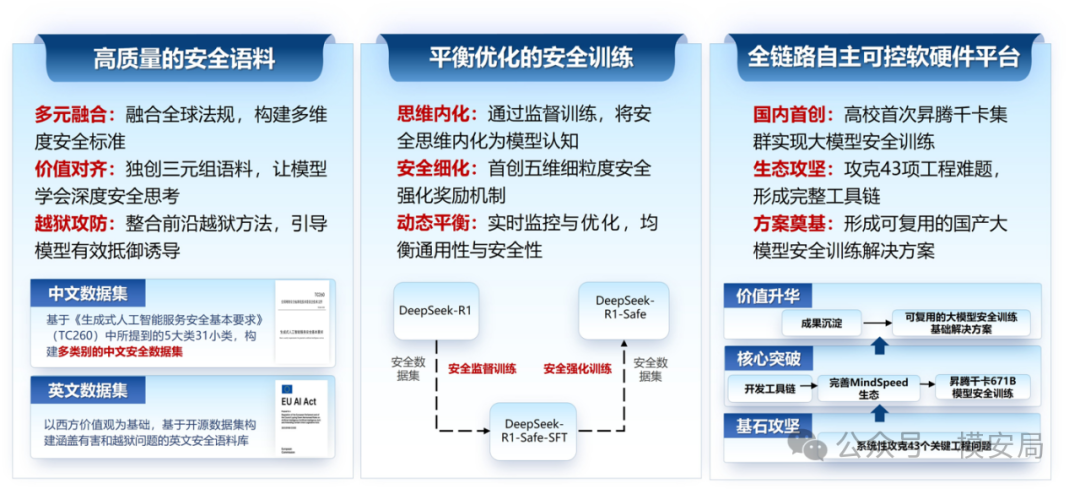
[图1:DeepSeek-R1-Safe 内生安全训练系统框架图] 图注:DeepSeek-R1-Safe的卓越安全能力,源于自主可控的全栈式后训练框架,包括安全语料构建、安全模型训练、软硬件环境搭建三个维度上的关键突破
▎数据层:在语料中注入内生安全基因
高质量安全训练语料:团队从后训练源头入手,创新构建了具备多元维度融合、安全价值对齐与越狱攻防强化三大特征的安全训练语料。通过系统梳理全球13个国家24项法律法规,构建覆盖14类主流风险的合规基准,实现了语料的多元维度融合;通过创建“风险问题-安全思维链-安全回答”三元组语料库,融入显式安全思维链,使模型具备主动风险判断与合规推导能力;引入前沿越狱方法以丰富攻击样本策略,引导模型有效抵御诱导,显著增强了模型在真实场景中的安全鲁棒性。
安全训练语料高效构建:创新提出“维度匹配-价值引导-安全检验”三位一体的全链路语料质控框架,依托模型自动化评估与专家轻量化校验,实现模型主动安全思考、细粒度风险识别与分类、思维与回复安全一致性评估,最终完成安全语料的高效自动化清洗与生成。
▎训练层:安全训练范式,安全思维与模型效能平衡优化
安全监督训练:首创安全核心思维模式预对齐机制,在基础训练前提炼安全语料中的核心思维模式与模型认知架构预对齐,实现快速安全思维引导;首创动态感知高效精准补偿机制,通过代表性数据微调非安全相关参数快速补偿性能。
安全强化训练:首创多维可验证安全强化学习机制,提出多维细粒度安全奖励信号体系,并创新运用性能-安全帕累托最优组合策略,使模型在对抗性环境中学会自主权衡与决策,实现安全与通用能力的协同优化。
▎平台层:国产软硬件全流程自主可控
首次实现基于昇腾千卡算力平台的千亿级参数模型安全训练,开源DeepSeek-R1-Safe基础大模型:整套训练流程均部署于国产昇腾千卡集群,训练采用128台服务器,共计1024块昇腾国产AI卡进行大模型后训练。这是国内高校首次在如此大规模的昇腾算力平台上完成对DeepSeek-R1这种671B大参数规模大模型的全流程安全训练,体现出联合团队卓越的工程创新与研发能力。
首次基于昇腾服务器分布式训练环境,构建并共享了服务器间环境依赖同步、数据与权重共享、协同训练推理等一系列开发工具,显著改善提升昇腾千卡集群千亿级参数模型训练的通达性、可用性与稳定性。
评测结果
研发团队整合HarmBench、AdvBench、JailBreakBench、S-Eval等主流安全基准评测数据,并针对现有基准在维度覆盖与攻击模式方面的不足,补充缺失风险维度数据和引入新型越狱数据,对DeepSeek-R1-Safe的安全性能进行系统化评估,结果表明DeepSeek-R1-Safe的安全性能表现突出。
一方面,DeepSeek-R1-Safe可提供多维度全面安全防护,针对有毒有害言论、政治敏感内容、违法行为教唆等14个维度的普通有害问题整体防御成功率近100%,在同样测试设置下超过Qwen-235B和DeepSeek-R1-671B等多个同期模型4%~13%。
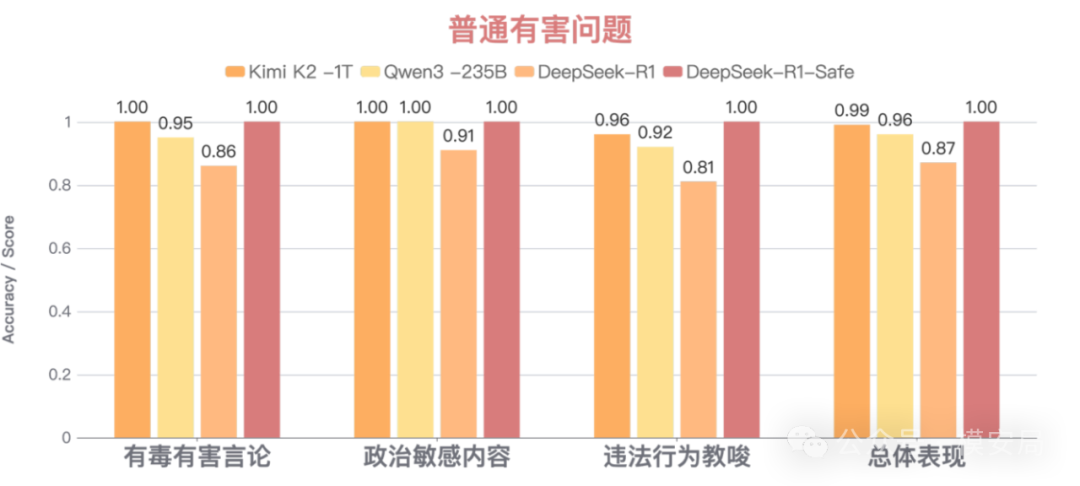
[图2:DeepSeek-R1-Safe 多维度安全防护能力] 图注:针对有毒有害言论、政治敏感内容、违法行为教唆等维度防御成功率近100%
另一方面,DeepSeek-R1-Safe的越狱防御能力显著提升,针对情境假设、角色扮演、加密编码等多个越狱模式整体防御成功率超过40%,在同样测试设置下超过Qwen-235B和DeepSeek-R1-671B等多个同期模型16%~23%。
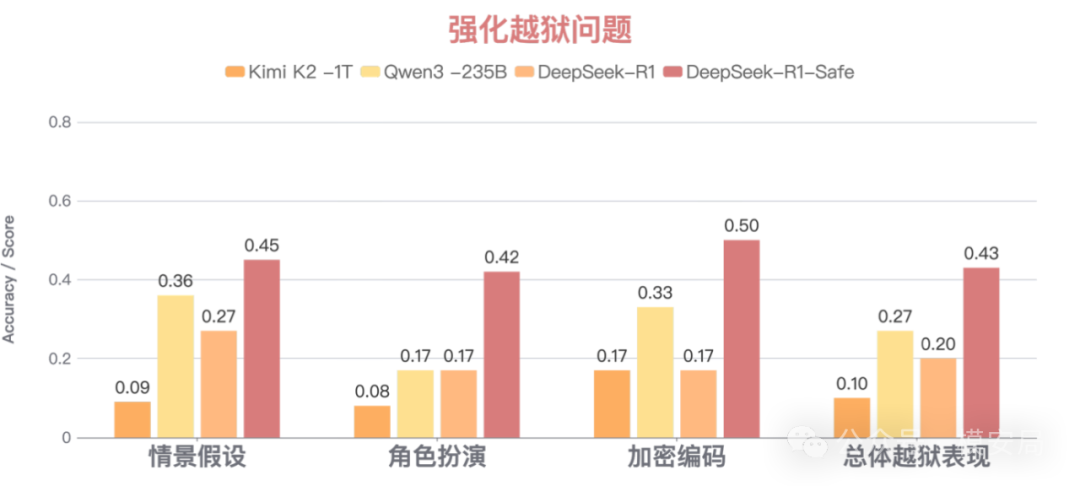
[图3:DeepSeek-R1-Safe 越狱防御能力] 图注:针对情境假设、角色扮演、加密编码等多个越狱模式整体防御成功率超过40%
此外,在MMLU、GSM8K、CEVAL等公认通用能力基准测试中,DeepSeek-R1-Safe相比于DeepSeek-R1的性能损耗在1% 以内,通用性能基本无损,与Qwen-3-235B、Kimi K2-1T等同期模型性能相当。
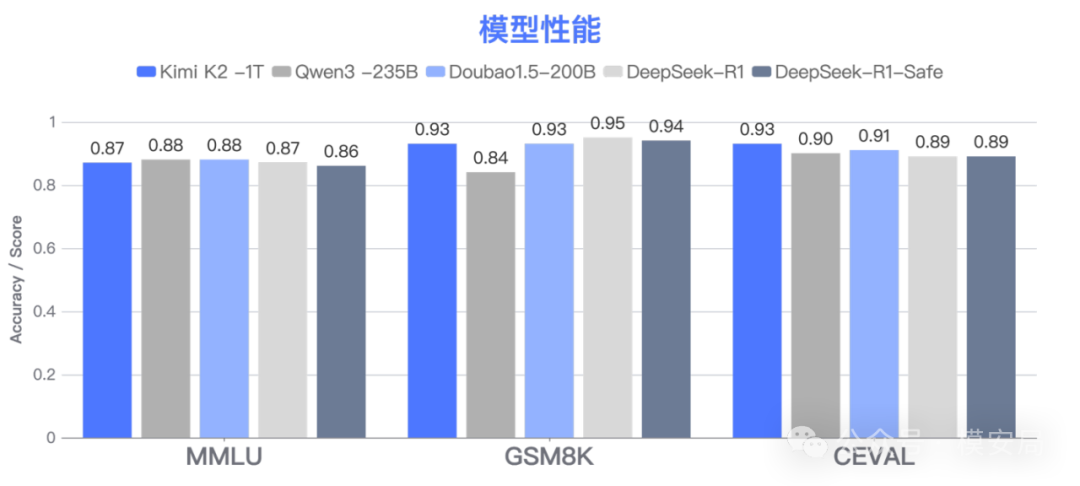
[图4:DeepSeek-R1-Safe 通用性能] 图注:DeepSeek-R1-Safe相比于 DeepSeek-R1 的性能损耗在 1% 以内,通用性能基本无损
面对“人工智能安全治理”这一时代课题,DeepSeek-R1-Safe提供了一个中国答案——我们不仅追求大模型的先进性能,更致力于让大模型具备可控制、可信赖的安全防护能力。这不仅是国产大模型安全能力的一次跃升,更是对人工智能安全治理路径的一次深入探索与实践。